The Visitor Design Pattern lets you separate the behavioral operation/algorithm from the actual objects themselves. This lets us change the objects and behaviour independently of each other. Let us see what this mean.
Consider the following domain. We want to model VMs across providers. This could be structured loosely as below:
class VM {
// Base attributes/methods
};
class GCPVM : public VM {
// GCP specialized attributes/methods
};
class AWSVM : public VM {
// AWS specialized attributes/methods
};
class AzureVM : public VM {
// Azure specialized attributes/methods
};
class OnPremVM : public VM {
// On-prem specialized attributes/methods
};
Now, consider the simple operation of shutting down VMs. Naturally, the powering off instructions are going to be different for each type of VM — The instructions to shutdown an on-prem VM is going to be different for say an AWS VM. Hence, we need to somehow invoke the right behaviour given the type of VM.
One way to work with this is to do the following (assuming there is a type variable that each specialized class sets). We could chain conditions like below:
// Shutdown all VMs
// Warning: Do not use raw pointers. Only for illustration
void shutdown_vms(std::vector<VM *> vms) {
for (auto vm : vms) {
shutdown_vm(vm);
}
}
// Call VM specific shutdown method
// Warning: Do not use raw pointers. Only for illustration
void shutdown_vm(VM *vm)
{
if (vm->type == VM.GCP) {
shutdown_gcp_vm((GCPVM *) vm);
} else if (vm->type == VM.AWS) {
shutdown_aws_vm((AWSVM *) vm);
} else if (vm->type == VM.Azure) {
shutdown_azure_vm((AzureVM *) vm);
} else if (vm->type == VM.OnPrem) {
shutdown_onprem_vm((OnPrem *) vm);
}
}
The problem with this approach is that this is extremely slow. Also, this strategy is prone to CPU branch prediction/speculation issues. Moreover in this strategy, latter conditions will take longer to execute since the CPU has to go through each of the earlier conditions. And, if you add a new type of VM — you need to modify shutdown_vm() method to add a new condition for that new VM, you plan to introduce. Another disadvantage is that the shutdown_vm() method needs to be copied across domains (lifetime, backup, etc) — where ever this functionality is needed. This violates separation of concerns and leads to hard to maintain code.
A Naive Approach #
Let’s put our object oriented hats to solve the above problem. We could introduce a method shutdown() in the base class (VM) and let each sub-class override the base method. Calling this method on the respective objects would perform platform specific task needed to shutdown the VM. This would loosely look like:
class VM {
// Base attributes/methods
...
// Sub-classes will override this method
virtual void shutdown();
};
The shutdown_vm() will then simply look like:
// Warning: Do not use raw pointers. Only for illustration
void shutdown_vm(VM *vm)
{
vm->shutdown();
}
This strategy would work for small projects but comes with its own disadvantages. Adding new operations would involve opening up existing sub-classes, specializing the new operation and recompiling them. For example, let us say we want to add a new operation to backup the VMs. Adding a backup() to the base class, that you expect all sub-classes to implement, will again result in re-opening each sub-class to implement the operation. Moreover, we end up lumping functionality into one single class that gets used across domains. This would again violate separation of concerns and cause various domains being bought together — since the VM class actually spans multiple domains. This would lead to hard to maintain/repetitive code. We also end up straying away from the core responsibility of the class with makes it harder to edit and reason about.
The Expression Problem #
The problem that we see here is a well studied one. This is named as such, since this was seen when trying to work with expression trees — when parsing. Bob Nystrom has beautifully explained the same. I will only add more words to his original explanation.
In an Object Oriented Programming paradigm, the relationship between the class and the methods it implements can be envisioned as a grid. The rows represent the related types and the columns represent the operations implemented by the types. This can be imagined as:
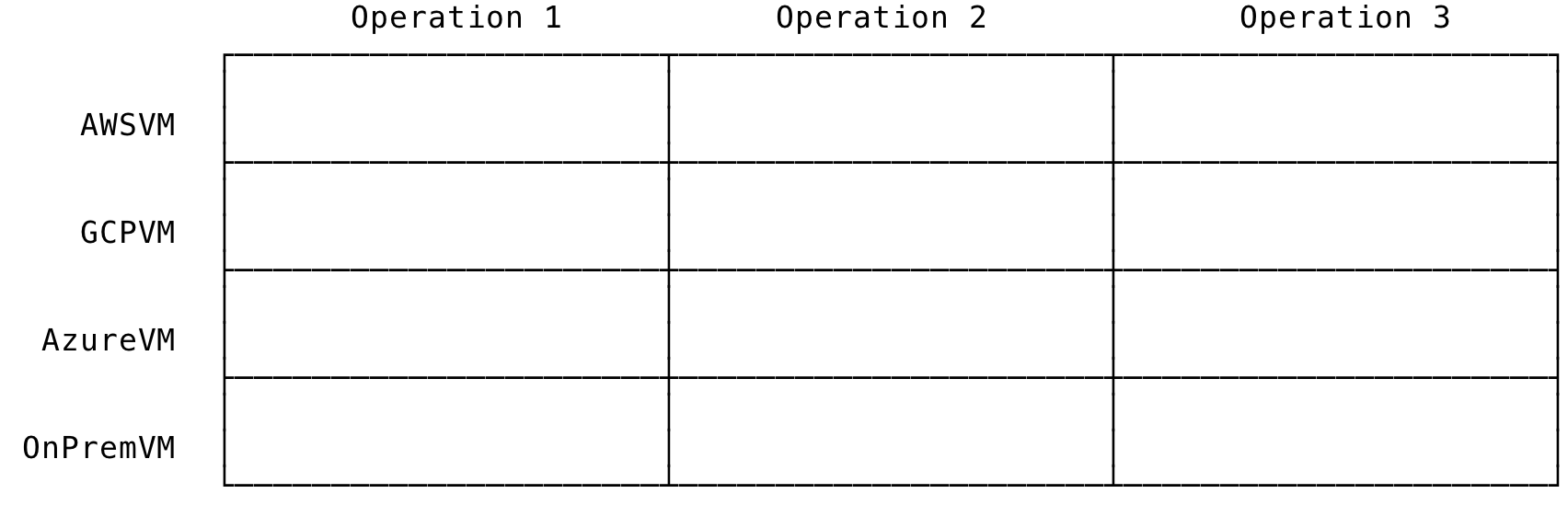
Fig 1: Type and Operations in OOP
If we add a new type, it is akin to adding a new row and implementing the operations in the columns:
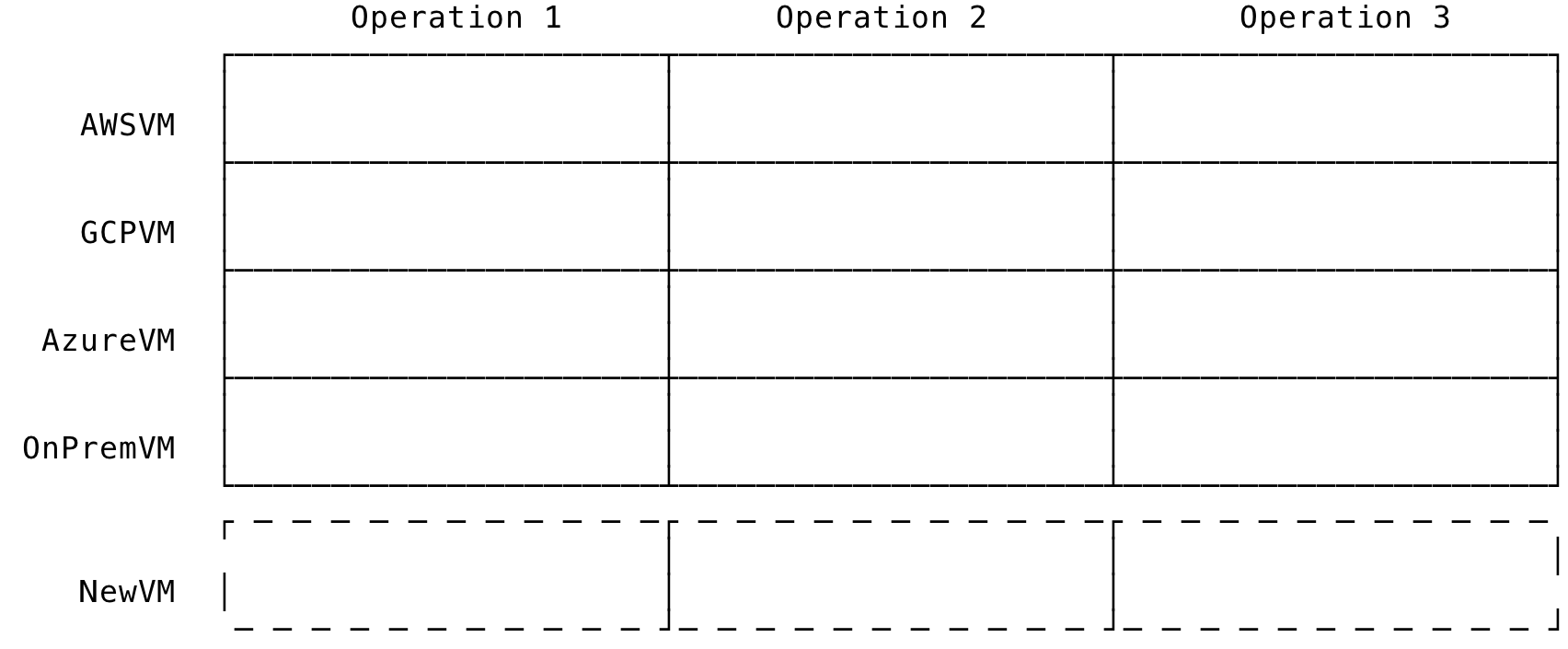
Fig 2: Add new Type in OOP
Similarly, adding a new operation means adding a new column to the types and all existing types has to be opened and the new operation implemented:
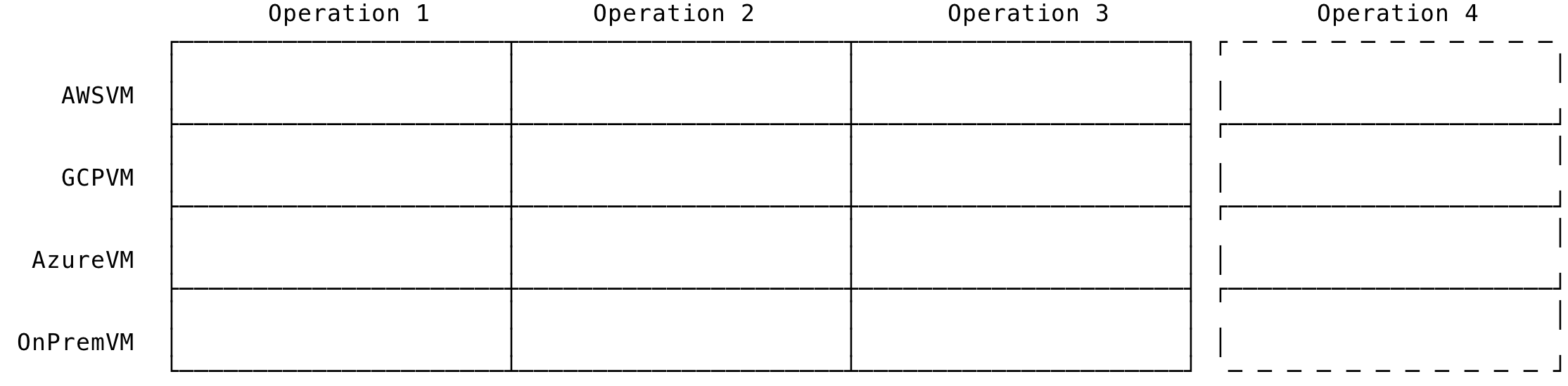
Fig 3: Add new Operation in OOP
As we can see, it is easy to add a new type if the operations are fixed. You do not need to re-open existing types for any modifications. But, if you want to add a new operation, existing types needs to be re-opened and the new operation implemented in all of the subclasses. This is the same exact problem that we saw earlier where we wanted to add a new operation (shutdown()) to be introduced.
Functional languages try to work with this in a different way. Types and functions are different from each other and insulated. You have a function and to have distinct behaviour for each type, the functions use pattern matching to differentiate between types to exhibit the right behaviour. In this paradigm, it is easy to add a new operation. A new function can be created to pattern match on all exiting types. But the problem is when adding a new type. This would involve opening up all functions and add a new pattern matching condition on the new type.
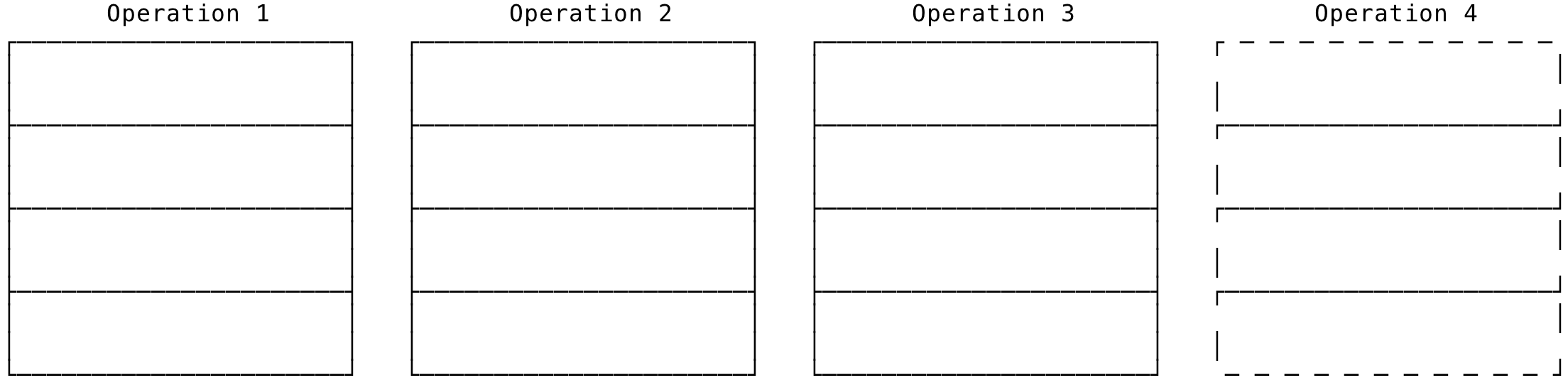
Fig 4: Add new Operation in FL
As you can see, in both the paradigms, it is not very easy to introduce both new types and new operations — independently of each other. This led to the discovery of the Visitor Design Pattern, which though not perfect, helps us in these situations — to introduce new types and new operations independently of each other.
The Pattern #
The Visitor Design Pattern is about easily adding rows(types) or columns(implementations) to the expression problem. The trick is to use another level of indirection to keep the types and the implementations separate. This pattern enables us to add new operations without having to add a new method to each class every time. The implementation of this pattern is broken up into an interface that contains the visit methods and the accept() method that dispatches the request to the right visitor, which each class needs to implement.
The interface in our VM example would look something like:
// Warning: Do not use raw pointers. Only for illustration
class VMVisitor {
virtual void visit_gcp_vm(GCPVM *vm) = 0;
virtual void visit_aws_vm(AWSVM *vm) = 0;
virtual void visit_azure_vm(AzureVM *vm) = 0;
virtual void visit_onprem_vm(OnPremVM *vm) = 0;
};
The interface has a concrete method to be called for each VM type. Now, any operation that needs to visit the VMs would be a new class implementing the above interface. The class representing the operation can then implement the concrete methods with the logic encapsulated for each of the type.
The class that is in-charge of shutting down VMs will now look like:
// Warning: Do not use raw pointers. Only for illustration
class VMShutdownManager : public VMVisitor {
void visit_gcp_vm(GCPVM *vm) { /*... */ }
void visit_aws_vm(AWSVM *vm) { /*...*/ }
void visit_azure_vm(AzureVM *vm) { /*...*/ }
void visit_onprem_vm(OnPremVM *vm) { /*...*/ }
};
This VMShutdownManager class implements the concrete logic needed to shutdown each of the VM.
Now comes the most important question. How do we link the VMShutdownManager to each of the VM type? This is where we make use of the accept() method, that will be implemented by each of the types. It’s responsibility is to link the operation class to the actual types. We define an accept() method in the base VM class that needs to be implemented by each of the concrete type. The VM class would now look like:
// Warning: Do not use raw pointers. Only for illustration
class VM {
void accept(VMVisitor *visitor);
};
And the concrete types would then implement them as:
// Warning: Do not use raw pointers. Only for illustration
class GCPVM : public VM {
// GCP specialized attributes/methods
/*...*/
void accept(VMVisitor *visitor) {
visitor->visit_gcp_vm(this);
}
};
class AWSVM : public VM {
// AWS specialized attributes/methods
/*...*/
void accept(VMVisitor *visitor) {
visitor->visit_aws_vm(this);
}
};
class AzureVM : public VM {
// Azure specialized attributes/methods
/*...*/
void accept(VMVisitor *visitor) {
visitor->visit_azure_vm(this);
}
};
class OnPremVM : public VM {
// On-prem specialized attributes/methods
/*...*/
void accept(VMVisitor *visitor) {
visitor->visit_onprem_vm(this);
}
};
And now, we can use the shutdown visitor to shutdown each of the VMs. The earlier shutdown_vms() method will now be:
// Shutdown all VMs
// Use the shutdown visitor to complete the task
// Warning: Do not use raw pointers. Only for illustration
void shutdown_vms(std::vector<VM *> vms) {
// Warning: Do not use new/delete. Only for illustration
VMShutdownManager *shutdown_manager = new VMShutdownManager();
for (auto vm : vms) {
vm->accept(shutdown_manager);
}
delete shutdown_manager;
}
We have now created a dispatch table that routes the accept() calls to the right visitor method for that type. If you look at it, we have added a column(operations) to the rows(types) without modifying the types (Although you need to introduce a accept() method to the hierarchy). Another important thing to note here is that, the dispatch is completely static and does not involve any runtime indirection.

Fig 5: Static Dispatch to the right operation
Also, the one accept() method added to the hierarchy can support as many visitors you want. For example, let us say we want to backup the VMs as part of some workflow. We could make use of the same accept() method to work with the VMBackupManager visitor implementation to backup the VMs in the system. This would look like:
// Backup all VMs
// Use the backup visitor to complete the task
// Warning: Do not use raw pointers. Only for illustration
void shutdown_vms(std::vector<VM *> vms) {
// Warning: Do not use new/delete. Only for illustration
VMBackupManager *backup_manager = new VMBackupManager();
for (auto vm : vms) {
vm->accept(backup_manager);
}
delete backup_manager;
}
Using this strategy, you can introduce visitors for operations that you want to insulate from the types and also have the flexibility to work with types and operations independently of each other.
One last point — if you want to return values from your visitor through the accept() method, it is easy to do so. Even easier if your language supports generics. Your visitor interface would now look like:
// Warning: Do not use raw pointers. Only for illustration
template<typename T>
class VMVisitor {
virtual T visit_gcp_vm(GCPVM *vm) = 0;
virtual T visit_aws_vm(AWSVM *vm) = 0;
virtual T visit_azure_vm(AzureVM *vm) = 0;
virtual T visit_onprem_vm(OnPremVM *vm) = 0;
};
And, the corresponding accept() method would look like:
// Warning: Do not use raw pointers. Only for illustration
T accept(VMVisitor<T> *visitor) {
return visitor->visit_right_vm(this);
}
You can then return a result from the visitor that the client can handle.
That’s it. Hope this post helped you in understanding the Visitor Pattern — using which we can add types and operations independently of each other. Also, the problems it solves, its limitations and things you need to look out for. For any discussion, tweet here.