The Strategy Design Pattern is a structural design pattern that lets you define a family of algorithms/strategies to perform some task. We encapsulate each one of them and make them interchangeable — through a common interface, and use them based on the factors involved. An algorithm that is encapsulated in this way is called a Strategy. This pattern is quite common and a very easy way to use multiple execution strategies to getting the task done.
Some examples of the Strategy Design Pattern are:
- Sending a notification on a transaction, to a customer, based on their communication preferences. The transaction object calls
send_notification(), to send the notification using the customer’s preferred medium - Sorting a set of numbers. You might want to use different sorting algorithms based on the size of the input or some other factors. You can use different strategies to sort the list, through a common interface such as
sort() - Making a beverage for someone to consume. They might be a tea/coffee/some other drink person and we might have an interface such as
make_beverage()and depending on the person’s preferences, we make him a tea or a coffee or something else entirely
As noted earlier, this pattern is quite common and you can see it everywhere in large codebases.
When Should This Pattern Be Used? #
The Strategy Design Pattern is mainly used when you need different variants of execution strategies — for a particular task at hand. The various strategies are related and will only differ in their behavior. The Strategy Design Pattern will make use of a context object that will own the strategy object, as part of its state. The strategy and the context objects interact to implement the chosen task. The strategy object will usually be assigned the appropriate behavior during the construction of the context object. This pattern also encapsulates the algorithms in the strategy object and the context object does not need to know anything about it. This in-turn creates an environment where each object has a clear set of responsibilities and is de-coupled from each other. This makes the objects easier to understand, maintain and change. Using the Strategy Pattern, we can avoid conditional statements in code to perform a particular task. The context object will be armed with the right strategy during construction and you can use it to get the job done.
Class Structure And Participants #
The class hierarchy of the Strategy Design Pattern is as below,
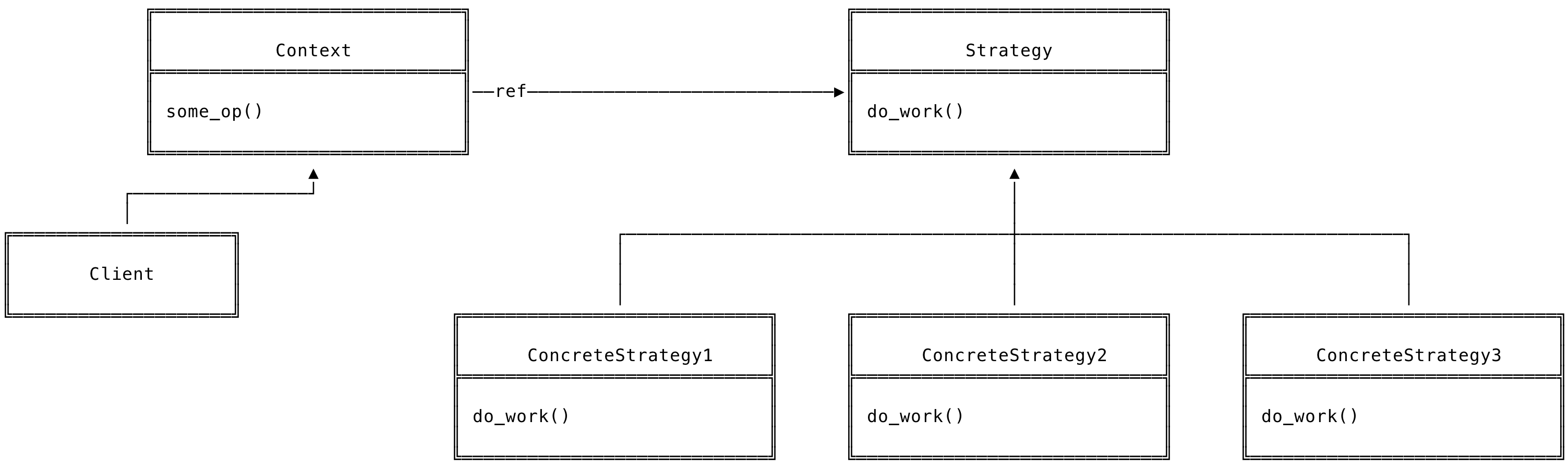
Fig 1: Class Structure - Strategy Design Pattern
Let us take a look at the participants in this design pattern.
Context: This is the object through which the Client uses a specific strategy. This object will be configured with the desired Strategy during its construction and it also maintains a reference to it.
Strategy: This declares the interface that all ConcreteStrategy objects implement. The Context object calls into this interface when wanting to run the algorithm.
ConcreteStrategy: This implements the algorithm specified by the parent Strategy interface.
Client: Client code that interacts with the classes used in this pattern.
Example Of This Pattern #
We shall look at an example that will help us understand this pattern. Suppose we want to write a janitor object to clean up older files in a given directory. Since there are multiple strategies as to how delete them, we will make use of a file purger object to encapsulate the various options available to us. The DiskJanitor is defined as follows:
The DiskJanitor will make use of a FilesPurger object to do the cleaning. The users of DiskJanitor will make use of the clean_files() to clean up files. The DiskJanitor internally calls into the FilesPurger object to do the work as follows:
void DiskJanitor::clean_files(const std::string &root)
{
_purger->purge(root);
}
Let us define the FilesPurger interface that various strategies will use.
In our demo, we will use three strategies to clean up files. The files will be deleted by — access time, modification time and the size of the file. Let us define purgers for each one of them.
The root variable of each purger will point to the directory that it will act upon. This will be passed over by the DiskJanitor object. To keep it simple, we will recursively iterate the directory, from the root, to clean up the files under the current directory. The MTFilesPurger and the ATFilesPurger will take in a time value rel_time and will clean up files less than that rel_time. The SZFilesPurger will take in a limit, in bytes, and will delete the files whose size is greater than the limit.
Let us now take a look at the various implementation of the purge() interface. The MTFilesPurger class can implement the purge() interface as below:
In this demo, we are using the std::experimental::filesystem classes to use the filesystem APIs. You need to link to c++fs to get this working. I will be sharing the project, so you can take a look there. In the code above, we are recursively iterating the filesystem and on all files that is not a directory, we make use of the system call stat() to get the file’s properties. And, if the difference is less than our relative time, we call remove() on it. To keep this demo simple, we are only checking if the file is not a directory before calling stat() on it. You might want to perform additional checks as you see fit. Also, this code is non-atomic and prone to race conditions. You need to use some sort of synchronization techniques to perform atomic work.
Similarly, the ATFilesPurger class can implement the purge() interface as below:
And the SZFilesPurger class can implement the purge() interface as:
And the code that uses the FilesPurger through the DiskJanitor will look like:
Depending on your requirements, you can choose to use a different purger and then your code will be,
std::unique_ptr<FilesPurger> purger =
std::make_unique<SZFilesPurger>(1000);
DiskJanitor janitor(std::move(purger));
janitor.clean_files("/Users/rajkumar.p/tmp");
Using the Strategy Design Pattern, you can have multiple algorithms to do your work and you can interchange them based on what you want to do. The structure of this pattern is similar to what we did above and this helps us encapsulate, understand and interchange various strategies. Additionally, to make this pattern strict, we can make all the concretestrategies’s methods private and only use the FilesPurger’s public interface.
Benefits Of This Pattern #
- Using the Strategy Design Pattern, we can define a family of algorithms and use them interchangeably to perform a particular task. Since these strategies are independent of the classes that use them, we can easily add new algorithms/strategies to the system
- Clients that need these strategies get more complex if they contain the algorithms within them. It makes the clients bigger, harder to reason, maintain and change. We can avoid these problems by defining classes that encapsulate the various strategies supported by the system, exactly what this pattern does
- The Strategy Design Pattern helps us in not exposing the complex, algorithmic specific data structures to the users of the various strategies. In our example above, the users of the FilesPurger do not need to know about how we are iterating the filesystem or the various state we maintain in the algorithms
- This pattern can be used to avoid unnecessary branching conditions in code. Without using the Strategy Design Patten, for example, to do the purge operation, you might use code like the below to get the job done,
void DiskJanitor::clean_files(const std::string &root)
{
if (use_mt_purge) {
purge_with_mt(root);
} else if (use_at_purge) {
purge_with_at(root);
} else if (use_sz_purge) {
purge_with_sz(root);
}
}
Here, instead of this, we make use of the Strategy Design Pattern to provide an interface to configure a class with one of the many behaviors
Implementation Notes #
- Inheritance can help in factoring out the common code that is run as part of the strategy. In our above example, we can make the FilesPurger have a method that does the recursive iteration of the directories and then call the
purge()that is implemented across purgers, which actually deletes the files based on their respective strategies. It would like something like,
- You can also also use inheritance to support various algorithms and strategies. You can subclass the context class and override it to provide your algorithm. This is static and cannot change during runtime, also makes it harder to understand, maintain and extend
- Usually, the context object passes all information need for the strategy object to do its work. But sometimes, the strategy object might need access to the context object. During these times, the context object passes itself, usually by ref, to the strategy object
- The main disadvantage of this pattern is that the clients need to be aware, at least by functionality, of the various strategies to use them to do some work. They might need to know how they differ and what state changes that they might effect
That’s it.
For any discussion, tweet here.
You can download the C++ project, that contains various design patterns featured in this blog, here.
[1] - C++ filesystem APIs
[2] - stat system call