Linux provides many facilities to share data between processes. Pipes can be used to pass data between related processes. By related, it means that the two processes can communicate as long as the pipe was created by some common ancestor. And, the data flows unidirectionally through a pipe - one end is used for reading and the other for writing. If we need to pass data in either direction – pipes might not be the right tool, although, you can still use two pipes to make it work.
The shell is a great example of using pipes to pass data between two related processes. A command like ls -l | wc, will get the shell to enable the flow of data from ls to the wc process. The shell needs to setup memory somewhere that will hold the output of ls that will in-turn be read by wc. This facility is provided by the Linux kernel using the pipe()/pipe2() system call. The shell requests some memory from the kernel and this is then used to pass data between the two processes.
To see this in play, let us trace the above shell command through strace:
$strace -f -e execve,pipe,pipe2,dup2,read,write sh -c 'ls -l | wc'
execve("/usr/bin/sh", ["sh", "-c", "ls -l | wc"], 0x7ffc4c1c3118 /* 39 vars */) = 0
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\237\2\0\0\0\0\0"..., 832) = 832
pipe2([3, 4], 0) = 0
strace: Process 59433 attached
strace: Process 59434 attached
[pid 59434] dup2(3, 0) = 0
[pid 59434] execve("/usr/bin/wc", ["wc"], 0x55a0a5e55c38 /* 39 vars */) = 0
[pid 59433] dup2(4, 1) = 1
[pid 59434] read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\237\2\0\0\0\0\0"..., 832) = 832
[pid 59433] execve("/usr/bin/ls", ["ls", "-l"], 0x55a0a5e55c08 /* 39 vars */) = 0
[pid 59433] read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\0\0\0\0\0\0\0\0"..., 832) = 832
[pid 59433] read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\237\2\0\0\0\0\0"..., 832) = 832
...
[pid 59433] write(1, "total 16\n-rw-rw-r-- 1 raj raj 3"..., 202) = 202
[pid 59434] <... read resumed>"total 16\n-rw-rw-r-- 1 raj raj 3"..., 16384) = 202
[pid 59434] read(0, "", 16384) = 0
[pid 59433] +++ exited with 0 +++
[pid 59434] write(1, " 5 38 202\n", 24 5 38 202
) = 24
...
+++ exited with 0 +++
Here, we run ls -l | wc (in a separate shell – to avoid optimizations, if any) and filter only on the relevant system calls. We also tell strace() to follow the fork() system call. You can see that the shell creates two processes – one each for ls and wc (PIDs 59433 and 59434 along with the two execve() calls in the output). This happens after the call to pipe2(), to set up the file descriptors that represents the shared kernel memory (pipe2() does the same work as the pipe() but with support for additional flags and is a Linux only API). Since the parent (the shell) has created the fds, that represent the shared memory, they are duplicated in the children that are eventually used to read/write. The dup() system call is called before the execve() on each child to correctly point the read and write ends of the children – ls’s output fd is piped to wc’s input.
Using pipes, you can have the two processes to read from and write to a pipe without waiting for each other. It does not matter if the reader is faster than the writer or vice versa. This is in stark difference to a command like ls -l > some_file;wc some_file where wc now has to wait for ls to finish before starting. The data too is stored in some temporary destination (which should be freed up manually) and passed around instead of just piping them directly.
pipe()/pipe2() System Call #
The pipe()/pipe2() system calls are defined as:
#include <fcntl.h>
#include <unistd.h>
int pipe(int pipefd[2]);
int pipe2(int pipefd[2], int flags);
The system calls take in a pair of fds and if the call succeeds, the fds returned is then used to access the common memory to read/write. The pipe2() system call takes in extra flags — the O_CLOEXEC, O_DIRECT and others. The shared memory is an unidirectional channel that is used by the co-operating processes. The pipefd[0] is used as the read channel and pipefd[1] is used as the write channel. By default, the read() on the pipe will block, if no data is available and the write() blocks if the pipe is full.
The system calls returns -1, if an error occurs and errno set accordingly.
Pipes can be loosely visualised as the below - Some process writes to an end and another process reads from the other. Also, the processes participating in this operation are related by a common ancestor.
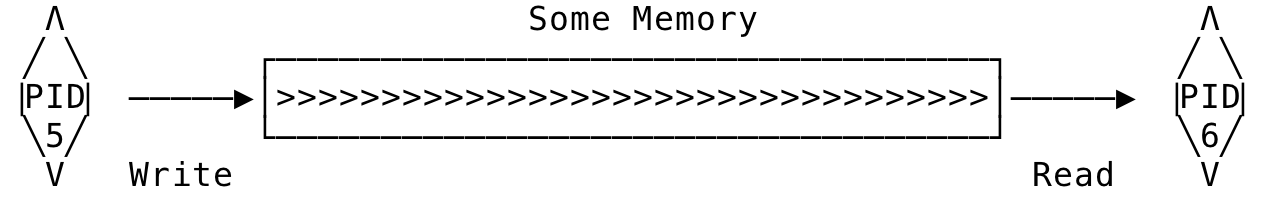
Fig 1: Pipe Visualisation
The next question then is, how large is this memory, that is allocated by the kernel? The memory, represented by the pipe, is limited. If this memory is completely filled up by the writing process, further writes will be blocked until data is read from the pipe. Older kernels limited this memory to a single page (usually 4096 bytes). Later kernels started allocating 2^16 bytes for pipes. And now, modern kernels the max is 2^20 bytes (1048576), which can be reduced by the call to fcntl(). On my system, the following is the value:
$cat /proc/sys/fs/pipe-max-size
1048576
As a general rule, you should not depend on the capacity of the pipe but instead focus on designing the program so as to efficiently read and write and not block indefinitely on either end.
Now, coming to the atomicity of write operations on a pipe – modern kernels will guarantee atomic writes up to 4096 bytes. So, even if many other processes are writing to the same pipe, a write of under or equal to 4096 bytes, will not interleave with other writes happening at the same time. If a process wants to write less than or equal to 4096 bytes, and if the pipe does not have enough capacity for the write, the kernel waits until the space is available and then completes the write. And, if the write is for more than 4096 bytes, the available space is filled up in the pipe and then the next write happens. If there is only one process, atomicity should not be a problem. With multiple processes, any writes greater than 4096 bytes will be interleaved with writes from other processes.
Program Structure when using Pipes and the Importance of close() #
When the pipe() system call is invoked by a process, the pipe’s read end is connected to the write end. This is a straightforward read on a write. This can be envisioned as:
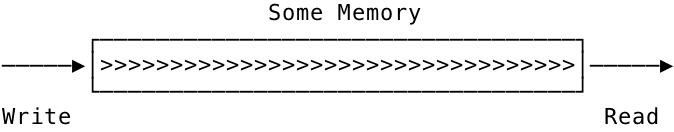
Fig 2: Pipe on a single process
As you can see, the pipe is not useful on a single process. The pipe as a communication medium comes into play only when multiple processes are involved. Once a fork() is issued, the pipe can now be visualized as:
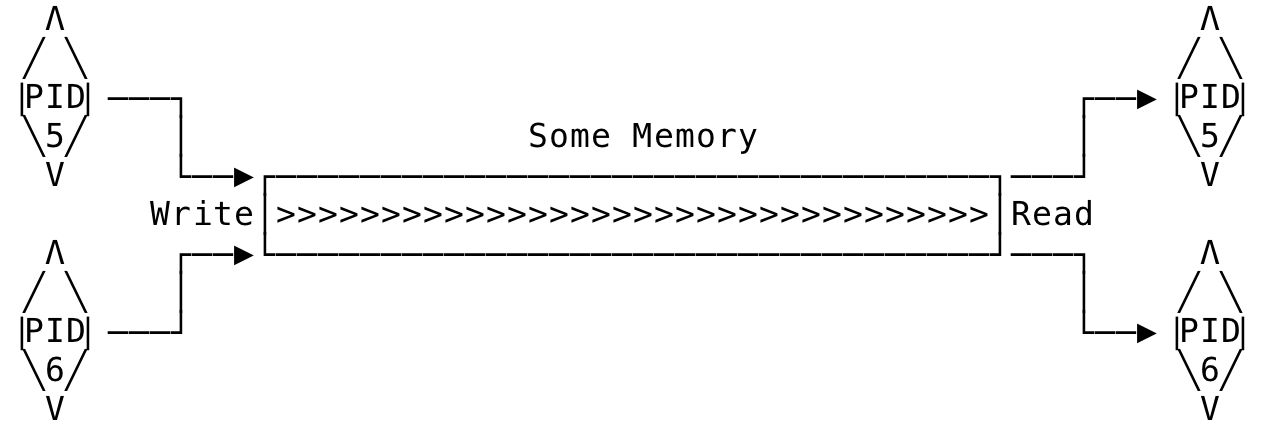
Fig 3: Pipe on multiple processes
Here, you can see the two ends of the two processes are connected to the read and write end respectively. A write on one end can now be read on the other. Still, the design looks off. Usually, one process is the producer/writer while another the consumer/reader. A process usually does not need to send data to itself.
And that brings us to the most important considerations when using a pipe — closing pipe file descriptors.
Closing pipe file descriptors not only releases resources back to the kernel but more importantly, closing a pipe fd specifies intent. When you close a write end of the pipe, it means that you are done writing and are letting the downstream readers know. Now, when some other process reads on the pipe, read() returns end-of-file — provided there are no other writers. Similarly, when you are done reading, the process can close the read end of the pipe and now the write() from another process returns with EPIPE (The kernel gets hit with a SIGPIPE signal) — provided there are no active readers. The right structure would look something like below:
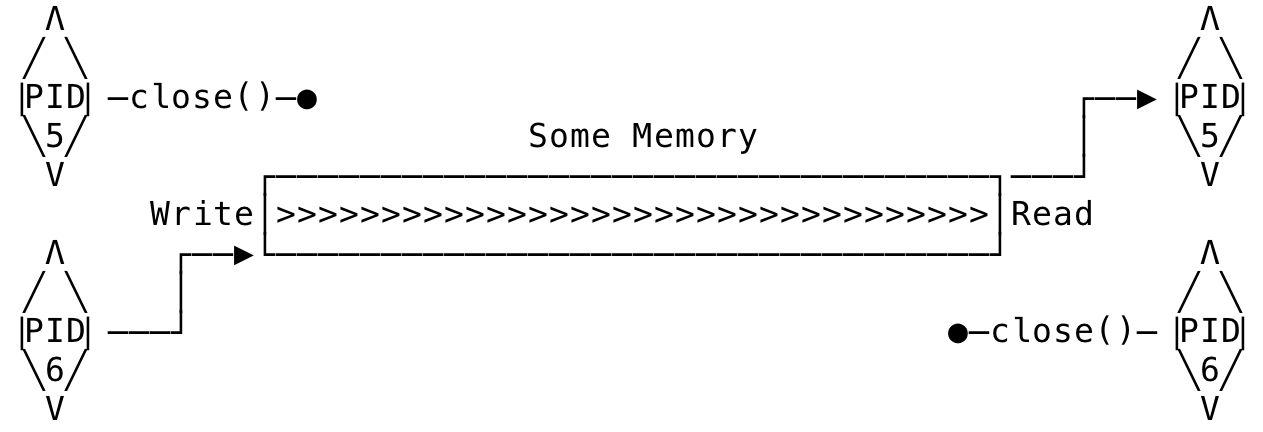
Fig 4: Pipe on multiple processes - The right way
In the above interaction, process with PID 6 is the writer and the process with PID 5 is the reader. Hence, the reader closes its write end and similarly, the writer closes its read end. Now we can coordinate the reads and writes between the process in a controlled manner and let the other know when the read/write is complete.
The main thing to keep in mind — a child inherits a parent’s open descriptors and this increases the reference count for that descriptor. Your program might block and run forever if the pipe fd references are not bought to zero, using close(). In essence, read() will block if there are write descriptors lying around and a write() will block if there are read descriptors are lying around (provided there is no data in the pipe).
What happens when simultaneous processes are trying to read/write to the same pipe? The order of the reads/writes is not guaranteed unless when using some form of synchronization. The kernel can schedule read/write in any order and is left to the program to order them.
To reiterate this section, it is not only right to close the not needed pipe file descriptors, but it is also the right way to use pipes. And if you find your pipe program hanging and not completing, then you might want to check your fds and if you closed them or not.
Now let us see a sample program where the parent tries to send data to a child using a pipe. The parent is the writer here whereas the child is the reader waiting for data from the parent.
In the above program, the parent first closes its pipe referencing the read end (line 48) and then writes the needed data. The child symmetrically closes its write end of the pipe and starts reading the data passed on by the parent. Once all data has been written, the parent also closes the pipe end for write thereby signalling it has completed write of all data. Now, when the child tries to read more data, it gets end-of-file and the child completes its work.
When running the program, you might get a similar output like the one below:
$./pipe
Parent with PID: 957871 executing...
Parent with PID: 957871, writing to child...
Completing write by parent with PID 957871
Child with PID: 957872 executing...
Child with PID: 957872, reading from parent...
BErGgTYpK6KoAGxKxIdzy4KdQIcTx2YfDVUIxmQAt3k6ErdzfBkBpAX4UpBEqi9f45TeFZWUUgONJ94IUKJqXYjGO28qCpR4zQPl2M4dPnMLbdXEwwtYsTo39g9GoJSqrzvdRvhPXlzUZRYQ91B7lE
Completed read by child with PID 957872
And remember, a read() will block on a pipe until there are open write ends and a write() will block if the pipe buffer is full. A read() will return end-of-file if all the write ends are closed and there is no more data in the pipe buffer. A write() on a pipe will return EPIPE if there are no readers for the pipe.
A Shell-like Program #
Let us now write a program to see how to use pipe()/pipe2() to pass data between a parent and children processes. We shall try to write a program that mimics a shell running two commands that are piped together. Let us try simulating the shell command - ls -lt | wc -l. Structurally, it will look like:
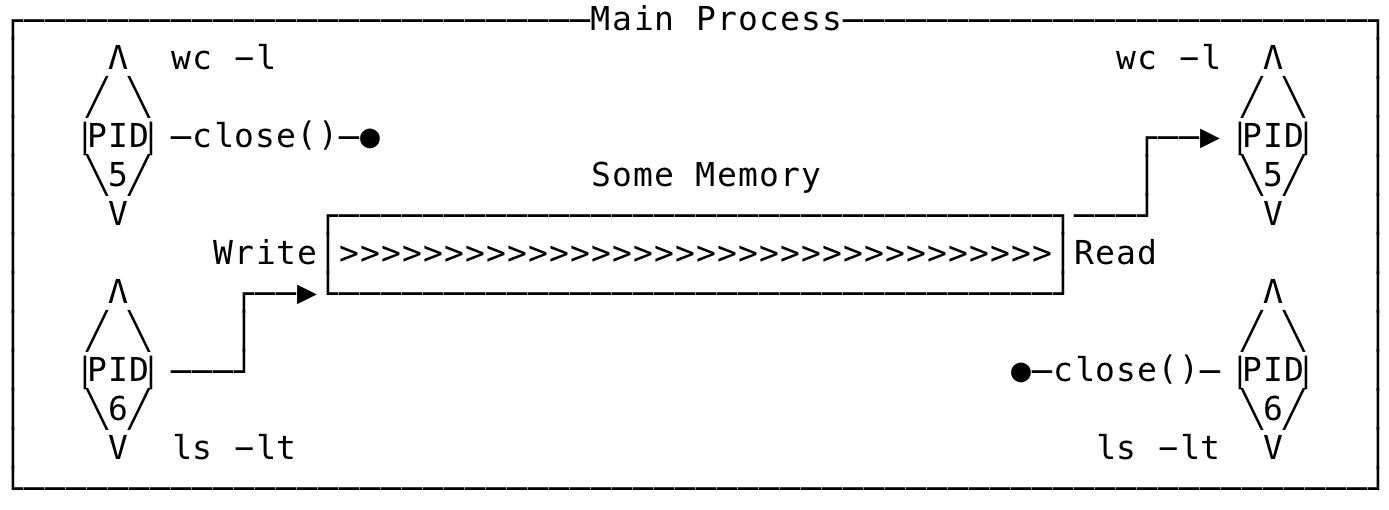
Fig 5: A shell like program
Here, the ls process is the writer to the pipe and the wc is the reader of the data that ls writes. The program for mimicking the shell command might look like the below:
Here too, we create a pipe and then fork. Now the child will inherit the parent’s pipe fds and the descriptors that are not needed, are closed. The writer writes to its write end that is then read from the read end of the reader. The structure flows logically like we discussed earlier. And when all the processes involved, signals completion (using close()), then the read/write will be completed.
The output for the above program would be something like:
$./pipe
Parent with PID: 766316 executing...
Child (ls -lt) with PID: 766317 executing...
Child (wc -l) with pid 766318 executing...
53
$ls -lt | wc -l
53
Using Pipes to Synchronize Processes #
To understand the importance of calling close() on the pipe file descriptors, let us see how closing the descriptors can help us synchronize related processes.
Remember, calling close() on the write end of the pipe, lets the downstream readers know that the read has completed — provided there are no other active writers and calling close() on the read end of the pipe, lets all the writers know that they can stop writing — provided there are no other active readers.
In the below code, we have a parent and child trying to work together to complete a task. The situation is that, the parent needs to wait for the child to complete before completing the set out task. We will accomplish this by using a pipe and communicate between the parent and child using close().
The code will look like something below:
Here, the children should execute before the parent and this is achieved by using a pipe. The children close their read end of the shared pipe and once done with their work, they close the write end of this pipe too. The parent meanwhile closes its write end of the pipe and waits for the children to complete their work. This is achieved by using a read() on the read end of the pipe. Since the children does not write to them and use it only as a signalling mechanism, the read blocks until all the children calls close() on the write end of the pipe. Once close() is called by all the children, the read() returns with end-of-file and the parent can now complete its task.
The output for the above program will look something like:
$./pipe3
Parent with PID: 3804956 executing...
Child 1 with PID: 3804957 executing...
Child 2 with PID 3804958 executing...
Child 2 with PID: 3804958 done executing.
Child 1 with PID: 3804957 done executing.
read() from parent. ret: 0
Parent with PID: 3804956 done executing.
That’s it for the Part I of this series. In the upcoming post, we will look at buffering as well as non-blocking I/O on pipes. We will also look at how pipes are implemented in Linux/XV6 and some tools to work with pipes.
For any discussion, tweet here.