In this post, we shall look at how Linux manages file descriptors — across multiple processes in the system along with the data structures used to do so. We shall also look at how the kernel uses the descriptors when system calls are made and how they are used/shared/duplicated.
A file descriptor is used to perform I/O in Linux. It is usually a positive number and is passed to system calls to read/write data. The kernel keeps track of what descriptor points to which file across which process. The file descriptor enables universal I/O that is so powerful in Linux — by which, we can use a common interface to read/write data across type of files — regular files, pipes, devices, terminals, sockets etc.
A file descriptor is created using the open() system call. This descriptor got from the system call can then be used in subsequent read() and write() calls. This is something like the below:
int fd = open(some_file, flags, mode);
// Read data from some_file
int n_read = read(fd, some_buf, buf_len);
// Write data to some_file
int n_written = write(fd, some_buf, buf_len);
// Release resources for that descriptor
close(fd);
All processes in Linux has the following file descriptors, numbered by default:
- 0 - Standard Input
- 1 - Standard Output
- 2 - Standard Error
And, as explained above, processes can use the open() system call to get descriptors to files that are of interest. The kernel is guaranteed to return the lowest number unused file descriptor, for that process, from the system call.
Kernel Data Structures for File Descriptors #
Multiple descriptors can refer to the same file — within a single process or across multiple processes. In-order to provide a layer of isolation between multiple processes and also enable sharing of file descriptors, the kernel manages a couple of data structures to facilitate this.
1) Per-Process File Descriptor Table #
The Linux kernel maintains a file descriptor table local to a process. When a process is created, this file descriptor table is also created and entries are added to it as in when the process creates new file descriptors. Calling close() on an open file descriptor removes the entry, for that descriptor, from this file descriptor table.
The table contains information if some flags are present on the open file descriptor and also has with it a pointer to the system-wide open file table (which we shall see next). You can think of it loosely like:
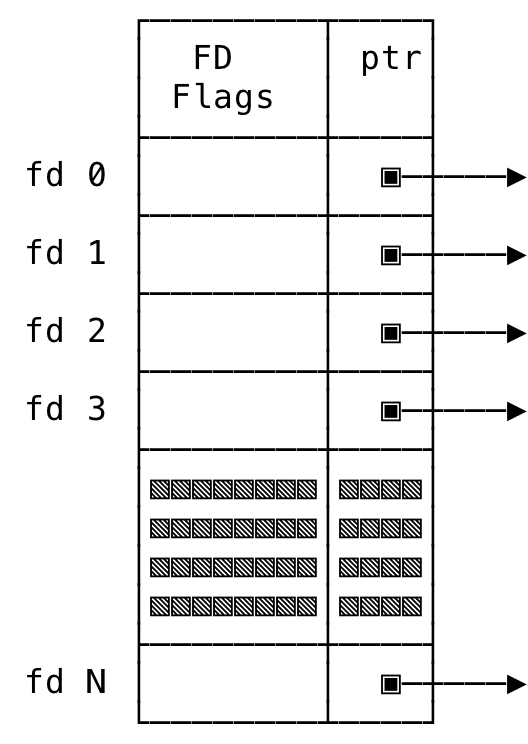
Fig 1: Per-Process File Descriptor Table
Note, the only flag that is tracked with this table is the presence of the close_on_exec flag. More information on close_on_exec can be found here.
2) System-Wide Open File Table #
This is a system-wide table of all open file descriptors — across all processes, that the kernel uses to isolate and share file descriptors. The per-process file descriptor table entry (looked at earlier) will point to an entry in this table.
Some of the information that gets stored in this table include:
- File Offset: The file offset for that particular open file. The offset gets changed on
read(),write()andlseek()system calls - File Status Flags: The flags that were specified as part of the
open()system call - File Access Mode: Mode as specified in the
open()system call - i-node Table Pointer: A pointer to the system wide i-node table that contains all the necessary information about the file (which we shall see next)
You can think of it loosely like:
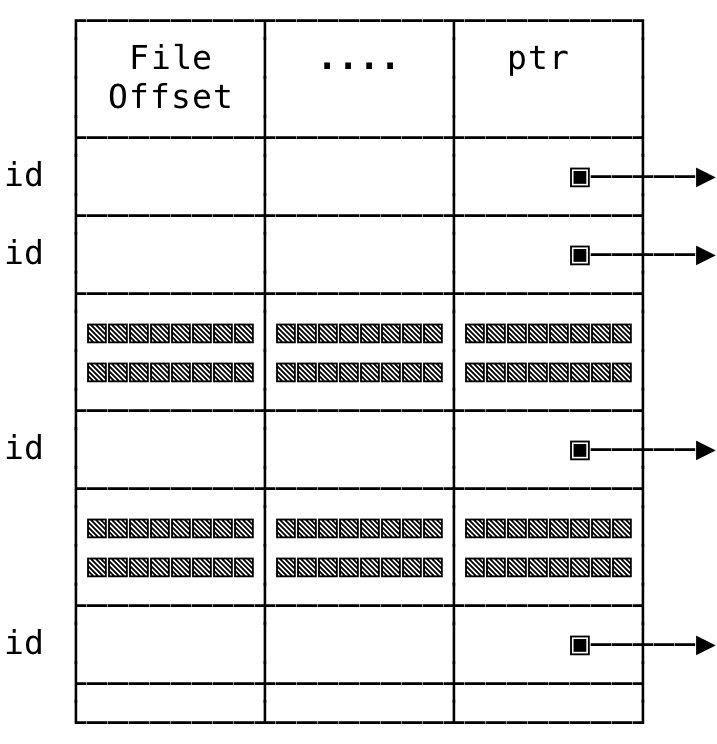
Fig 2: System-Wide Open File Table
This table also has other information relating to signal driven I/O and others and as explained, this structure is system-wide.
3) System-Wide i-node Table #
This is a system-wide table of all files in the file system. Note that this is a in-memory copy of the i-node present on disk and the kernel will sometimes not have all files’ i-node in memory. In-memory i-node objects will be created as in when necessary. The system-wide open file table entry (looked at earlier) will point to an entry in this table.
Some of the information that gets stored in this table (associated with the i-node) include:
- File Type: If the file is a regular file, directory, device etc.
- Permissions: Permissions on that file
- Metadata: Information like modification time, access time, size etc.
- Locks: Any locks on the file
- Pointer to Blocks: The pointer to the data blocks on disk
You can think of it loosely like:
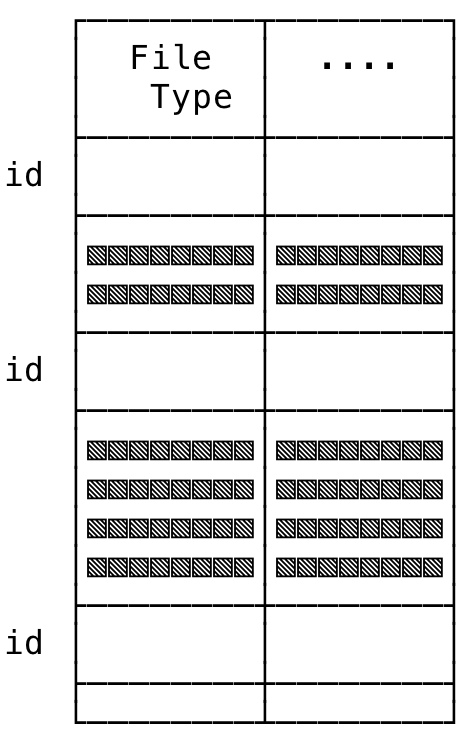
Fig 3: System-Wide i-node Table
Now, the three tables seen above come together, loosely, as:
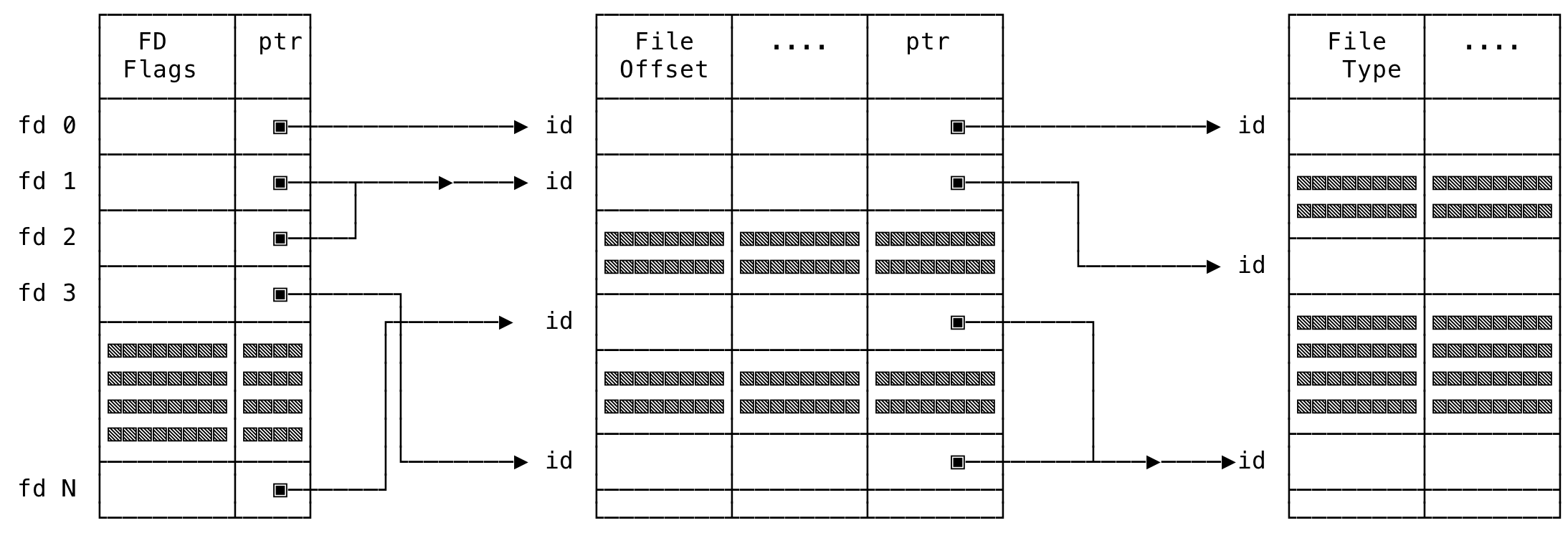
Fig 4: File Descriptor Data Structures
And as explained above, this is a system-wide table common to all processes within the system.
System Calls and File Descriptors #
Now, let us look at how these data structures come into play when various system calls are made.
Multiple Open() Calls #
When multiple open() system calls are made, from within the same process — for the same file, like the below:
// fd to file_xyz
int fd1 = open(file_xyz, flags, mode);
// Read on fd1
int n_read = read(fd1, some_buf, buf_len);
// fd to file_xyz
int fd2 = open(file_xyz, flags, mode);
The three structures are manipulated — due to these system calls, as:
- Per-Process File Descriptor Table: There will be two entries in this table due to the two
open()system calls that was made. Both the entries will be in the same table since the calls were made in the same process - System-Wide Open File Table: There will be two entries in this table too since the offsets vary. Read and writes on the file will be directed through this table using the offsets for that entry for that file descriptor
- System-Wide i-node Table: There will be only one entry in this data structure. This is because, although both the descriptors are different, the underlying file is the same and will have a single i-node entry
Loosely, the data structures might look like:
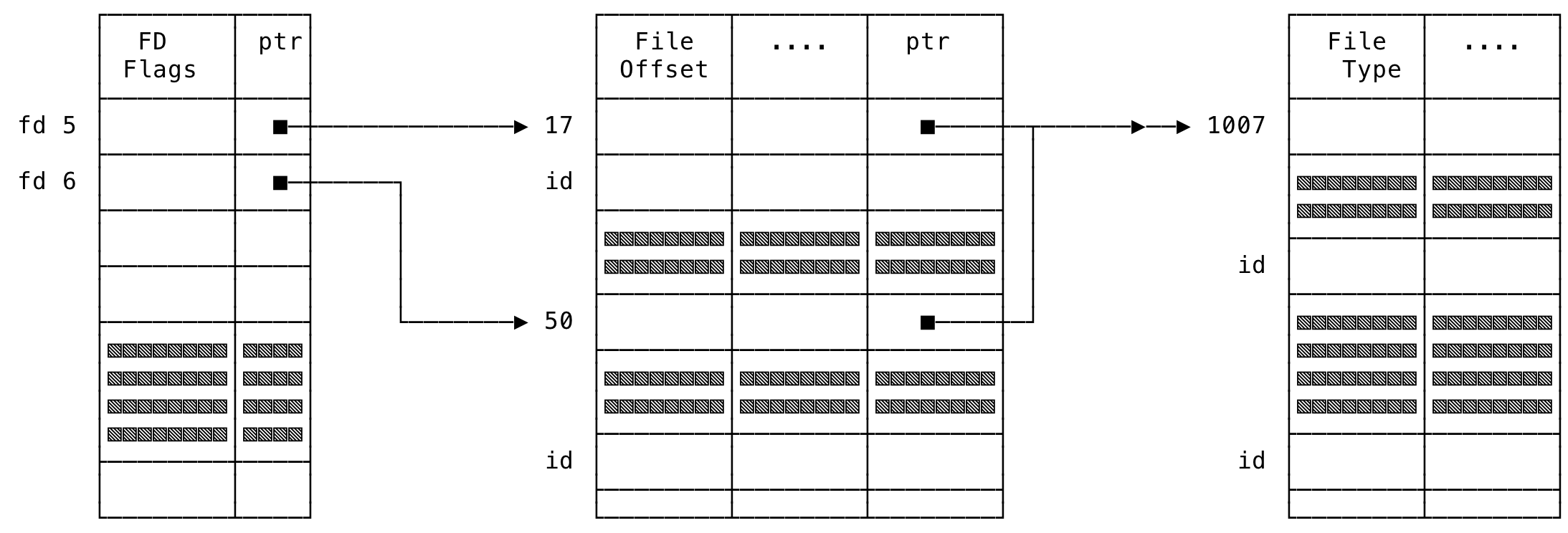
Fig 5: File Descriptor Data Structures - Multiple open(), same process
File Descriptors After fork() #
Consider the following code:
int fd = open(some_file, flags, mode);
// Read data from some_file
int n_read = read(fd, some_buf, buf_len);
// Do something
// ...
// Create multiple processes
int pid = fork();
if (pid == -1) {
// Error
} else if (pid == 0) {
// Child
// fd is shared with parent
} else {
// Parent
// fd is shared with child
}
Here, the fd is going to be shared by the parent and the child. Now let us see what the entries will look like in the various kernel data structures.
- Per-Process File Descriptor Table: Each process will have a table for its file descriptors. The entry for the file descriptor -
fd, will be present in both the processes’ file descriptor table - System-Wide Open File Table: Since, the underlying file file is shared between the parent and the child and hence has the same offset, there will only be one entry for the file in this table and both the parent and the child will point to this entry
- System-Wide i-node Table: There will be only one entry for this data structure pointing to the file’s i-node entry
Loosely, the data structures might look like:
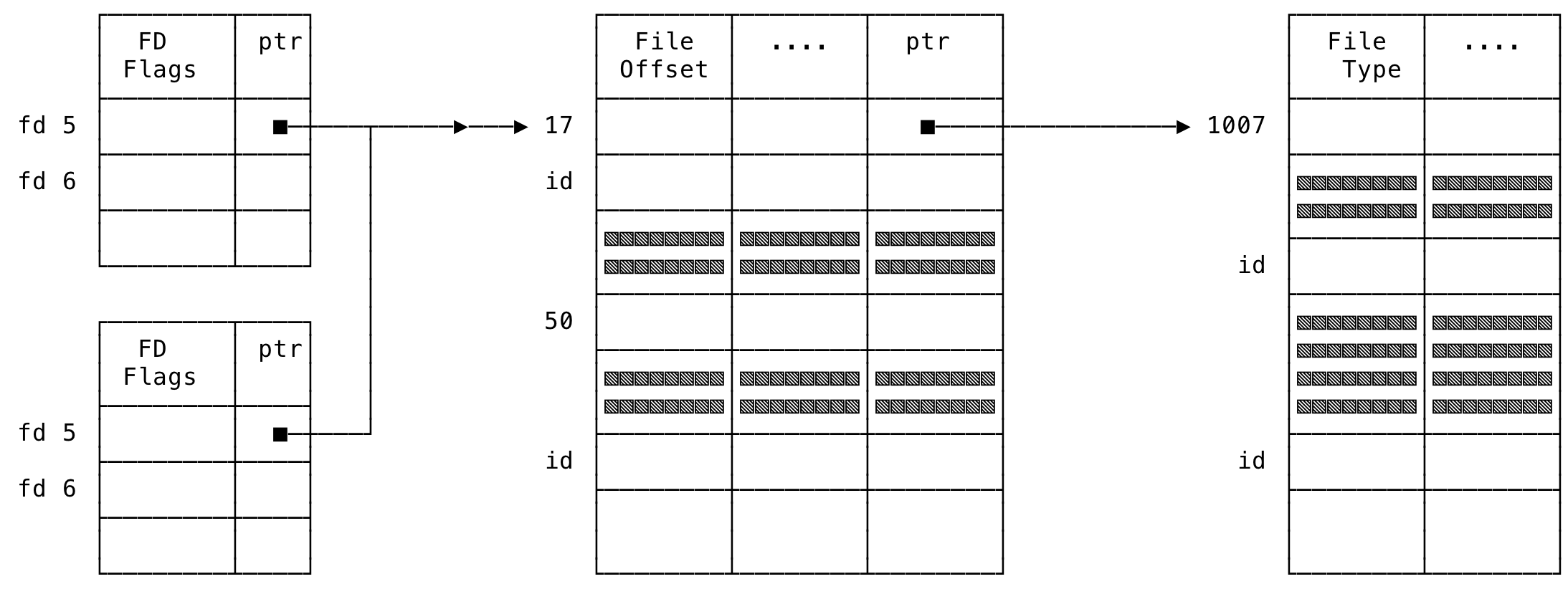
Fig 6: File Descriptor Data Structures - fork()
dup()/dup2()/dup3() System Calls #
The dup(), dup2() and the dup3() system calls are used to duplicate a file descriptor. Details can be found for the various dup()/dup2()/dup3() calls here.
Before the duplicating the file descriptors, the file descriptors might refer to totally different files with different offsets. This might look like:
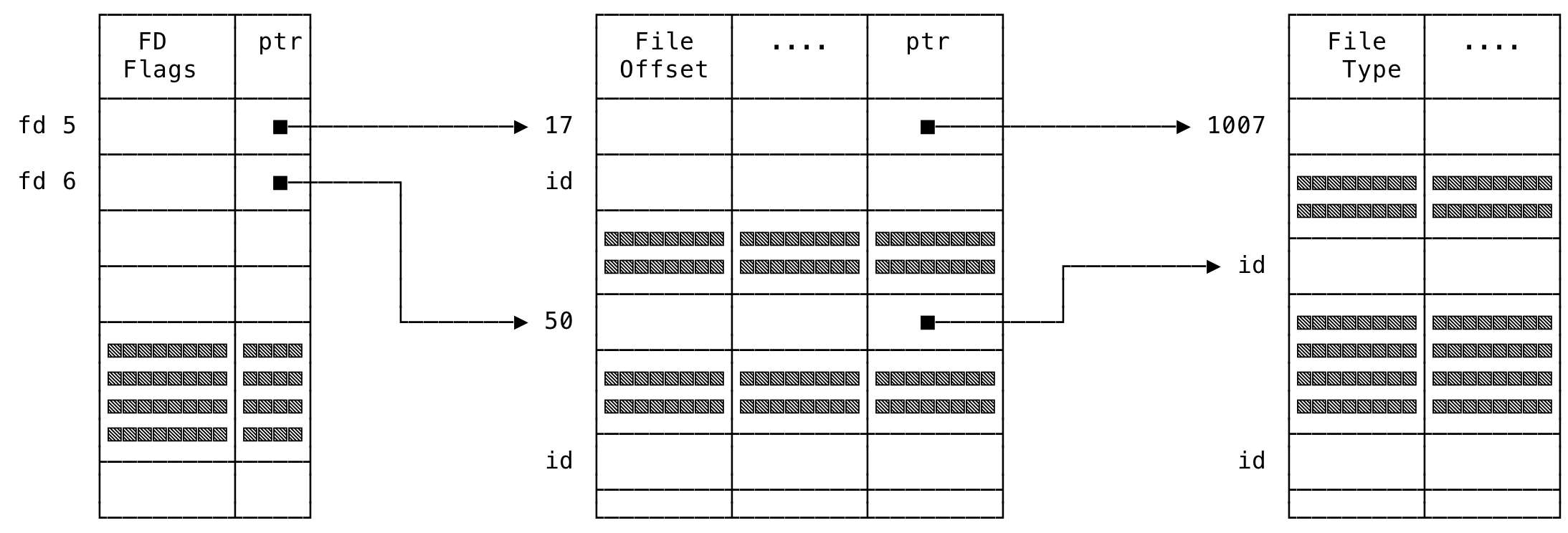
Fig 7: File Descriptor Data Structures - Before dup()
And after making the dup2() system call like:
int ret = dup2(5, 6);
// Do something
The file descriptors 5 and 6 will now refer to the same file and the entries will point to the same underlying file. The data structures will now look like:
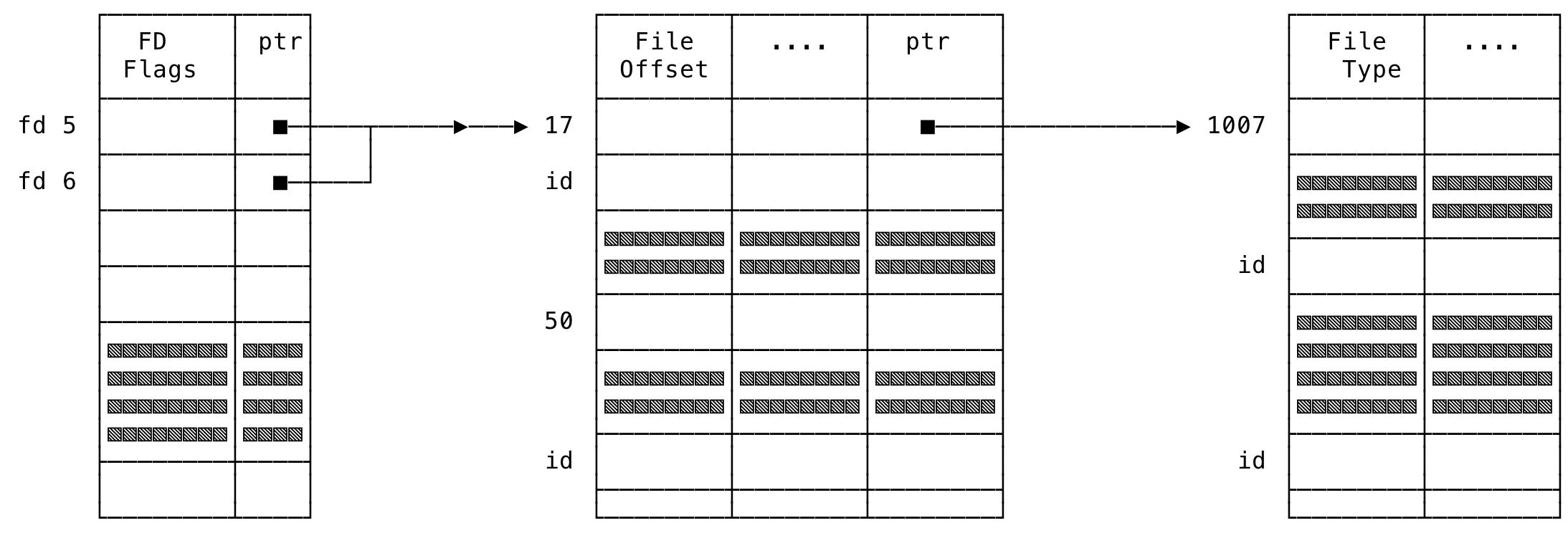
Fig 8: File Descriptor Data Structures - After dup()
This is what happens beneath when you duplicate a file descriptor, in the shell like:
$some_command > output_file 2>&1
Above, the standard output is set to the output_file and also the standard error is duplicated to the same output_file. The data structures would be modified by the kernel to reflect this.
That’s it. I hope, by illustrating the data structures used by the kernel to manage file descriptors, it has become easy to reason about them and see how they are manipulated by various system calls. Also, it will give you a better understanding about what is private and what is shared underneath by the kernel. For any discussion, tweet here.
[1] http://man7.org/tlpi/
[2] https://man7.org/linux/man-pages/man2/dup.2.html